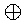 BnCn-1
BnCn-1
library ieee;
use ieee.std_logic_1164.all;
use ieee.std_logic_arith.all;
use ieee.std_logic_unsigned.all;
entity alu is
port (
a, b: in std_logic_vector(7 downto 0);
opcode: in std_logic_vector(2 downto 0);
x: out std_logic_vector(7 downto 0)
);
end alu;
architecture arch of alu is
begin
process (a, b, opcode)
case opcode is
when I_AND => x <= a and b;
when I_OR => x <= a or b;
when I_NOT => x <= not a;
when I_XOR => x <= a xor b;
when I_ADD => x <= a + b;
when I_SUB => x <= a - b;
when I_ACC => x <= a;
when I_DAT => x <= b;
when others => x <= "XXXXXXXX";
end case;
end process;
end arch;
package alu_pack is
constant I_AND: std_logic_vector(2 downto 0) := "000";
...
end alu_pack;
偙偺ALU偺VHDL婰弎偦偺傕偺偼丄堄奜偲扨弮偱丄峴偆墘嶼傪巜掕偡傞
opcode偺抣偵墳偠偰丄弌椡x傪丄擖椡a, b偐傜媮傔傞幃傪
case暥偱愗傝懼偊偰偄傞偩偗丄偱偡丅
(偪偵傒偵屻敿偺package埲壓偱丄墘嶼偺巜掕偵巊偭偰偄傞
I_AND側偳偺掕悢偺抣傪掕媊偟偰偄傑偡丅C尵岅偱偺#define偺傛偆側傕偺偲
棟夝偟偰偍偄偰偔偩偝偄)
偙偙偱偪傚偭偲柺敀偄偺偼丄偦偺榑棟崌惉寢壥[p.77乽榑棟夞楬恾乿]偱偡丅 1價僢僩暘偺ALU偼丄擖椡偱偁傞a[n], b[n]偐傜偄傠偄傠側墘嶼夞楬傪捠偟丄丄 偦偺偆偪偺1偮傪opcaode偵傛偭偰丄僙儗僋僞傪巊偭偰慖傇丄偲偄偆 峔惉偵側偭偰偄傑偡丅(仸僙儗僋僞偼[p.67]嶲徠) 忋偐傜4偮偺榑棟墘嶼偼丄偦偺傑傫傑丄側偺偱偡偑丄 恀傫拞偺壛嶼丒尭嶼偺偲偙傠偑丄偪傚偭偲堦岺晇偑偁傝傑偡丅 opcode=100偺偲偒偼丄x偼a+b(壛嶼)側偺偱丄壛嶼婍傪捠偟偨 寢壥偑x偵弌偰偒傑偡偑丄偙偺壛嶼婍偺cin(壓偺寘偐傜偺寘忋偘)偼丄 壓敿暘偺恾偐傜傢偐傞傛偆偵丄嵟壓埵價僢僩偺ALU偱偼丄opcode[0]偵 側偭偰偄傑偡丅 opcode=100(壛嶼)偺偲偒偼丄opcode[0]=0偱偡偺偱丄 傑偝偵寘忋偘揱攄壛嶼婍(RCA)偺峔惉偲側傝傑偡丅
偲偙傠偑oppcode=101(尭嶼)偺偲偒偼丄壛嶼婍偺b懁偵偼 b[n]傪NOT僎乕僩傪捠偟偨傕偺(/b)偑梌偊傜傟偰偄傑偡丅 傑偨偙偺偲偒opcode[0]=1偱偡偺偱丄慡懱偲偟偰偼丄 乽a + /b + 1乿偑媮傔傜傟傞偙偲偵側傝傑偡丅 偲偙傠偑丄/b + 1 偲偼丄b偺乽2偺曗悢乿偱偡偺偱丄 2恑悢偺悢偲偟偰偼丄b偺晞崋傪斀揮偟偨傕偺(-b)偲摨偠堄枴偲側傝傑偡丅 (2偺曗悢偵偮偄偰偼丄偙偙側偳傪嶲徠) 偮傑傝弌椡x偼丄乽a - b乿偲摨偠堄枴偲側傝丄尭嶼偑峴傢傟偰偄傞偙偲偵 側傝傑偡丅
壛嶼懳徾偺2偮偺1價僢僩偺悢An, Bn偲丄慜偺寘偐傜偺 寘忋偘怣崋Cn-1傪壛嶼偟丄偦偺寢壥Sn偲丄師偺寘傊偺 寘忋偘怣崋Cn傪惗惉偡傞偺偑丄1價僢僩偺壛嶼婍偱偁傞 慡壛嶼婍 (full adder; FA)偱偟偨丅 偙偺慡壛嶼婍偺弌椡偱偁傞Sn, Cn偺偆偪丄Sn偼
BnCn-1
Bn (揱攄崁)
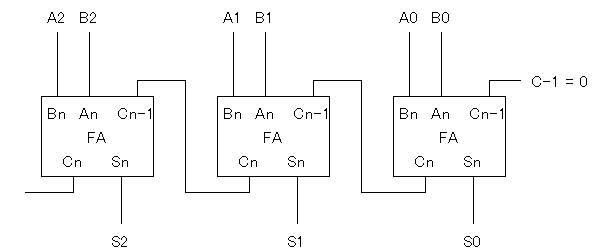 儕僾儖僉儍儕乕壛嶼婍偱偼丄慜偺寘偺寘忋偘(僉儍儕乕)偑
師偺寘偺擖椡偵偮側偑偭偰偄傑偡偺偱丄嵟戝偱偡傋偰偺寘丄偮傑傝
寘悢暘(=N)偺僉儍儕乕偺揱攄偑婲偙傞偙偲偵側傝丄
慡懱偲偟偰壛嶼偑廔椆偡傞傑偱偺帪娫(墘嶼帪娫)偼
寘悢N偵斾椺偡傞丄偲偄偆栤戣揰偑偁傝傑偡丅
Bn (揱攄崁)
儕僾儖僉儍儕乕壛嶼婍偱偼丄慜偺寘偺寘忋偘(僉儍儕乕)偑
師偺寘偺擖椡偵偮側偑偭偰偄傑偡偺偱丄嵟戝偱偡傋偰偺寘丄偮傑傝
寘悢暘(=N)偺僉儍儕乕偺揱攄偑婲偙傞偙偲偵側傝丄
慡懱偲偟偰壛嶼偑廔椆偡傞傑偱偺帪娫(墘嶼帪娫)偼
寘悢N偵斾椺偡傞丄偲偄偆栤戣揰偑偁傝傑偡丅
Bn (揱攄崁)
偨偲偊偽4價僢僩壛嶼婍傪偮偔傞偲偟偰丄 偙偺惗惉崁偲揱攄崁傪弴斣偵彂偔偲師偺傛偆偵側傝傑偡丅
| G0 = A0丒B0 | P0 = A0B0 |
C0 = G0 + P0丒C-1 |
| G1 = A1丒B1 | P1 = A1B1 |
C1 = G1 + P1丒C0 |
| G2 = A2丒B2 | P2 = A2B2 |
C2 = G2 + P2丒C1 |
| G3 = A3丒B3 | P3 = A3B3 |
C3 = G3 + P3丒C2 |
B1){A0丒B0 + (A0B0)丒C-1}
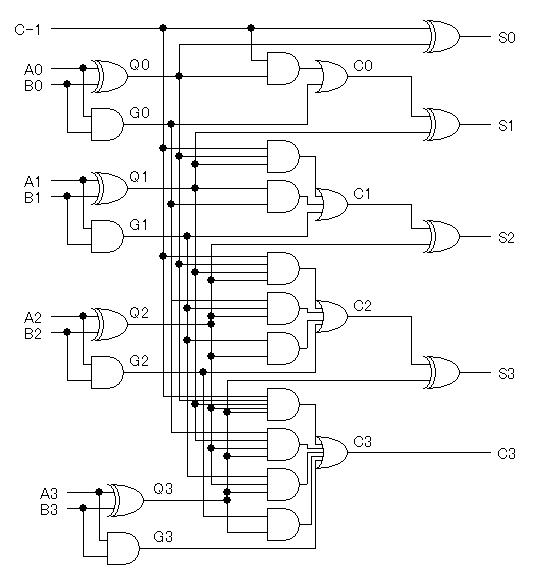
偙偺傛偆偵CLA偼寘悢偑懡偔偰傕崅懍側墘嶼偑壜擻偱偡偑丄 寘悢偑懡偔側傞傎偳丄僉儍儕乕Cn傪媮傔傞偨傔偺榑棟幃偑 媫寖偵暋嶨偵側傝丄榑棟夞楬偑戝婯柾偵側偭偰偟傑偆偲偄偆栤戣偑偁傝傑偡丅 (尦婥偑偁傞恖偼8價僢僩CLA偱傕嶌偭偰傒傑偟傚偆丒丒丒) 尰幚揑偵偼CLA偺峔惉偼4價僢僩暘偵偲偳傔丄偦傟埲忋偺價僢僩悢偺 壛嶼婍偑昁梫側応崌偼丄4價僢僩CLA傪偮側偘傞丄偲偄偆峔惉傪偲傞偺偑 堦斒揑偱偡丅
1001 丗旐忔悢(X)
亊) 0101 丗忔悢 (Y)
----------
1001 丗晹暘愊
0000
1001
0000
---------
0101101 (0x2d = 45(dec))
忔悢Y偺奺寘偵懳偟偰丄旐忔悢X傪弴斣偵偢傜偟偰
暲傋偰偄偒丄嵟屻偵偡傋偰傪懌偡傢偗偱偡偑丄
搑拞偺丄旐忔悢X傪弴斣偵偢傜偟偰偄偭偨崁傪
晹暘愊偲屇傃傑偡丅
晹暘愊傪媮傔傞偺偼娙扨偱丄
旐忔悢Y偺丄偦偺寘偑1偱偁傟偽X偦偺傕偺丄
偦偺寘偑0偱偁傟偽0丄偲側傝傑偡丅
[p.75]偺恾偼丄偙偺傛偆側曽朄偵傛傞8價僢僩偺忔嶼婍(暲楍忔嶼婍)偺 椺偱偡丅 寢嬊1寘偺2恑悢偺忔嶼偼丄AND墘嶼偦偺傕偺偱偡偐傜丄 偦傟偧傟偺晹暘愊xi丒yj傪AND僎乕僩偱媮傔偮偮丄 忋偐傜壓傊懌偟偰偄偔壛嶼傪峴偆夞楬傪暲傋偰偄偗偽傛偄偙偲偵側傝傑偡丅 偙偺傛偆側峔惉偺忔嶼婍傪暲楍忔嶼夞楬偲屇傃傑偡丅
暲楍忔嶼夞楬偱偼丄晹暘愊偺抜悢丄偮傑傝忔悢Y偺寘悢暘偲 傎傏摍偟偄悢偩偗壛嶼婍偑暲傃傑偡偺偱丄 偙偺抜悢偑丄慡懱偺墘嶼帪娫傪寛傔傞傕偭偲傕戝偒側梫場偲側傝傑偡丅
徻嵶偼徣棯偟傑偡偑丄忔悢Y偵懳偟偰丄師偺傛偆側Yj傪媮傔傞偲丄 Y偺價僢僩悢偺敿暘偺悢偺Yj傪壛嶼偡傞偩偗偱 忔嶼寢壥傪媮傔傞偙偲偑偱偒傞丄偲偄偆傕偺偱偡丅 乮偨偩偟yj偼丄忔悢Y偺j價僢僩栚乯