第2回: マイクロプロセッサとDSP
マイクロプロセッサ
コンピュータや携帯電話をはじめとする情報機器の
ほとんどすべてに、小型コンピュータが入るようになりました。
この小型コンピュータは、その機器全体の制御をしています。
たとえば
- キーが押されたらそれに反応する
- 音を出す
- ディスプレイに画像を表示する
- 画像を圧縮・伸張する
- 通信(無線通信など)をする
など、まさに心臓部というべきはたらきをしています。
一般にこのような小型コンピュータを
マイクロプロセッサ(μP)と呼びますが、
小型でもコンピュータの一種ですので、
いわゆる「ノイマン型」コンピュータであることが
ほとんどです。
つまりメモリに入っているプログラムを順番に読み出し、
その手順どおりに処理、つまり演算やデータの受け渡しを
行う、というものです。
したがってマイクロプロセッサ以外にもメモリ、
さらにほとんどの場合は入出力装置が必要となるわけで、
それらを接続するために、一般には「バス型」の接続をとります。
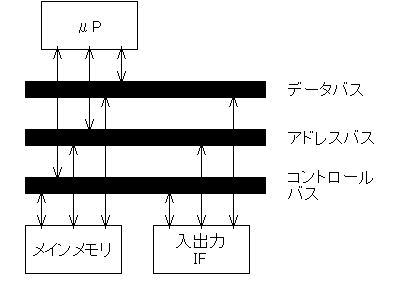
これは、マイクロプロセッサやメモリなどを個別に接続するのではなく、
「バス」と呼ばれる共用の信号線にすべてを接続し、
そこを順番に使ってデータのやり取りを行う方式です。
マイクロプロセッサの内部構成
マイクロプロセッサの動作に、バスがどのように使われるか、
具体的にみてみましょう。
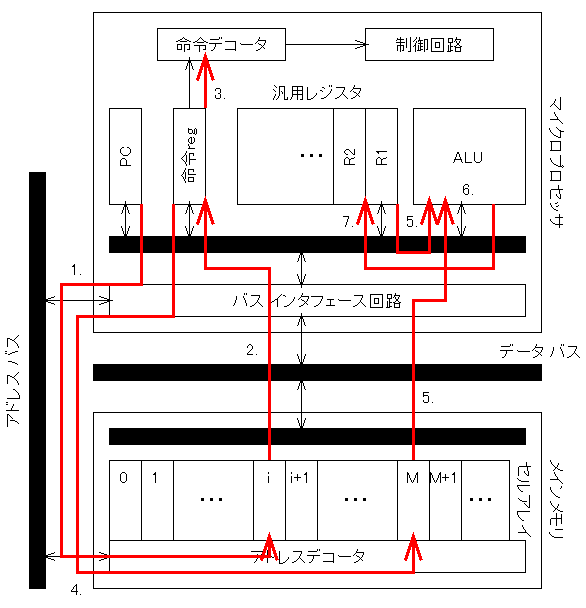
これは、プロセッサ内部のメモリ(レジスタ)R1の中の
D1という数値(データ)と、メインメモリのM番地に入っている
D2というデータに対して、D1-D2を計算し、その結果をR1に
戻す、というプログラム(命令)を実行する場合の
データの流れです。
以下のような手順で、バスを通ってデータが流れていることが
わかります。
- プログラムカウンタ(PC)が示す番地iが、バスインタフェース回路を
通してアドレスバスに出力され、メインメモリのi番地が選択される
- この番地に入っている数値(データ)を命令とみなして読み出し、
バスインタフェース回路を通して命令レジスタに入る
- 命令デコータが、この数値(データ)が示す命令の処理内容を解読する
- メインメモリ内のデータが入っている番地Mを計算し(アドレス計算)、
アドレスバスに出力する
- メインメモリのM番地のデータを読み出し、ALUに渡すとともに、
レジスタR1のデータD1もALUに渡される(オペランド読み出し)
- ALUで、所定の演算(この場合は減算)を行う
- ALUでの演算結果をR1に書き込む
このデータの流れを制御するのも、マイクロプロセッサの
役割であり、それを指定するのが、プログラム中の「命令」であるわけです。
ディジタル信号処理プロセッサ(DSP)
マイクロプロセッサは非常に広い場面で用いられるわけですが、
特に通信分野での信号の処理には次のような特性があり、
一般のマイクロプロセッサでは性能が足りない場合があります。
- 高速処理が必要
- 積和演算(A×B+Cを求める演算: 行列の演算で多用される)
そのため、これらの用途では、性能を高めるために
アーキテクチャを工夫したプロセッサが用いられることが多く、
このような特殊なプロセッサをディジタル信号処理プロセッサ
Digital Signal Processor; DSP)と呼びます。
具体的には、次のようなアーキテクチャ上の特徴をもつものが
多いようです。
- 乗算を高速に行う専用回路(乗算器)を持つ
- 乗算器と(累算機能つきの)加算器をつなげた積和演算専用の
回路(データパス)を持つ
- 命令とデータを別々のメモリに持ち、それぞれ専用のバスを持つ
- メモリ内のデータを示すための専用レジスタ(アドレスポインタ)を持つ
以下、このうちの2つについて見ていきましょう。
積和演算回路
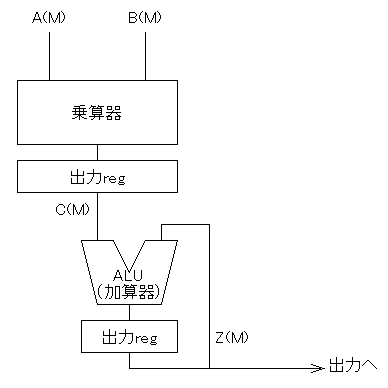
一般に積和演算回路はこのような構成をとります。
この動作を順に考えてみましょう。
- 被演算数A(M), B(M)が乗算器に与えられる(このA(M), B(M)は、時刻を追って
順にメモリから供給されるとする)
- 少し時間がたったあと、その乗算結果C(M)=A(M)×B(M)が現れる
- そのC(M)を、次のクロック周期のはじめに出力レジスタに保持する
- その結果C(M)が、1つ前の周期の積和演算結果Z(M-1)とともに
ALU(この場合は加算器)に入り、その出力にはZ(M)=C(M)+Z(M-1)が現れる
- そのZ(M)を、その次のクロック周期のはじめに出力レジスタに保持する
(つまりZ(M) = C(M) + Z(M-1))
つまり時刻を追ってみると次のようにZ(M)が変わっていくわけです。
- C(0) = A(0)×B(0) → Z(0) = A(0)×B(0)
- C(1) = A(1)×B(1) → Z(1) = Z(0) + C(1) = A(0)×B(0) + A(1)×B(1)
- C(2) = A(2)×B(2) → Z(2) = Z(1) + C(2) = A(0)×B(0) + A(1)×B(1) + A(2)×B(2)
- ...
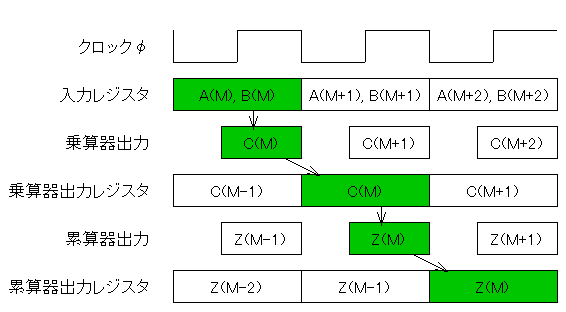
このようにして、積和演算ΣA(i)×B(i)が求められていくわけです。
この演算回路では、2クロック周期分送れて結果が累積されていくので、
2段パイプライン構成と呼びます。
ハーバードアーキテクチャ
ノイマン型コンピュータの動作で、案外高速化の足かせになるのが、
いわゆるノイマンボトルネックと呼ばれる、メモリからのデータの読み出しの
部分です。
特に命令とデータがともにメモリに入っていますから、
両者を順番に読み出すのは、効率が悪そうです。
そこで命令とデータを別々のメモリに入れておいて、
同時に読み出せるようにしよう、というのが
ハーバード・アーキテクチャと呼ばれるアーキテクチャ(構成)で、
DSPでは多用されます。
(逆に同一メモリに命令もデータも格納するアーキテクチャを
プリンストン・アーキテクチャと呼びます)
先に紹介したDSPの例でも、ハーバードアーキテクチャをとっていることが
わかります。
高性能化のための機能設計
これらのデータの流れをふまえ、
マイクロプロセッサやDSPを設計するときには、
まず全体のデータの流れ(データフロー)を考えなければなりません。
つまりスムーズにデータが流れるようなアーキテクチャを
考える必要があります。
(ちなみに「アーキテクチャ(architecture」とは、もともとは
建築用語で、建物の構造のことを指しますが、
プロセッサの設計にあたっても、まさに「アーキテクチャ」の
「デザイン」が必要になるわけです)
アーキテクチャの設計にあたっては、次のようなことを
考慮するべきです。
- データ形式(数値が整数か、固定小数点か、浮動店小数点か、など)
- 命令形式(数値で命令をあらわす体系。命令長(ビット数)と
必要な命令の数、レジスタの数などによって決まります)
- レジスタ形式(どの程度の規模の内部レジスタをもつか、など)
- アドレス方式(仮想記憶を使うか、など)
- 割り込み方式(割り込みの種類、割り込み処理ルーチンへの移行方法など)
これらは、いわばプロセッサのアーキテクチャの根本で、
必要な機能・性能や、利用可能な回路規模などをふまえながら、
総合的に判断する必要があります。
続いて、どのようなレジスタや演算器などの機能ブロックを、
どのように配置・接続してデータパスを作るか、という
機能設計を、次のようなことを考慮しながら行います。
- パイプライン方式(段数、ステージ、分岐命令の対応など)
- バス方式(レジスタと演算器を何本のバスで結ぶか、など。
当然バスの数が多いほど性能は高くなるが、バスが占める「面積」が大きくなる)
- 搭載機能(乗算器の有無、メモリ管理機構の有無、など)
- 並列処理(スーパースカラ方式、など)
これらの設計(デザイン)が済んだら、実際の論理回路、
さらにはVLSI(のレイアウト)へと設計を進めていくわけです。
この回のソボクな疑問集
戻る